import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gamma
from scipy.special import gamma as gamma_func
from scipy.optimize import minimize
# Dữ liệu đầu vào (giá trị x và f(x) dưới dạng %)
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47])
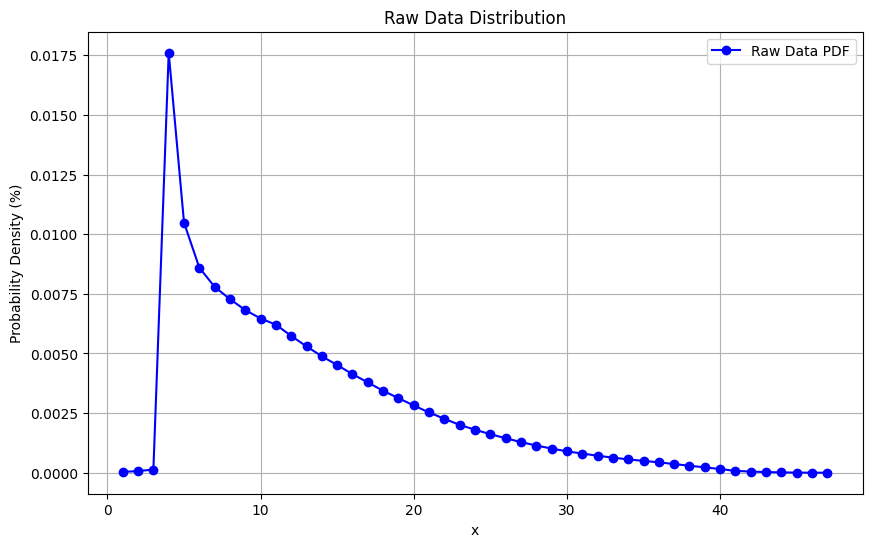
fx = np.array([0.000038, 0.000067, 0.000136, 0.017609, 0.010485, 0.008596, 0.007793,
0.007277, 0.006820, 0.006466, 0.006208, 0.005735, 0.005297, 0.004883,
0.004514, 0.004133, 0.003786, 0.003436, 0.003127, 0.002820, 0.002527,
0.002262, 0.002005, 0.001804, 0.001616, 0.001447, 0.001285, 0.001141,
0.001015, 0.000897, 0.000805, 0.000714, 0.000633, 0.000560, 0.000497,
0.000438, 0.000363, 0.000294, 0.000226, 0.000155, 0.000078, 0.000050,
0.000028, 0.000015, 0.000006, 0.000003, 0.000001]) # Chuyển % thành phần thập phân
# Chuẩn hóa dữ liệu để tổng bằng 1
fx_normalized = fx / np.sum(fx)
# Hàm PDF của mô hình hỗn hợp Gamma
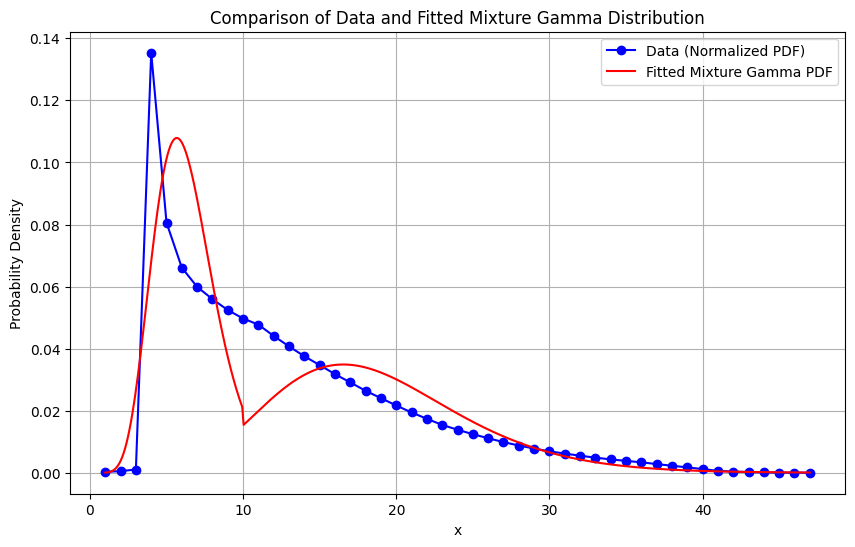
def mixture_pdf(x, p, k1, theta1, k2, theta2):
pdf1 = p * gamma.pdf(x, a=k1, scale=theta1) if x <= 10 else 0
pdf2 = (1 - p) * gamma.pdf(x, a=k2, scale=theta2) if x > 10 else 0
return pdf1 + pdf2
# Hàm log-likelihood cho mô hình hỗn hợp Gamma
def log_likelihood(params, x, fx):
p, k1, theta1, k2, theta2 = params
p = min(max(p, 0.01), 0.99) # Giới hạn p trong [0.01, 0.99] để tránh lỗi
n = len(x)
ll = 0
for i in range(n):
total_pdf = mixture_pdf(x[i], p, k1, theta1, k2, theta2)
if total_pdf > 0:
ll += fx[i] * np.log(total_pdf)
return -ll # Minimization, nên trả về giá trị âm
# Giá trị ban đầu cho các tham số
initial_params = [0.75, 2.0, 2.0, 4.0, 1.0] # [p, k1, theta1, k2, theta2]
# Tối ưu hóa sử dụng minimize
result = minimize(log_likelihood, initial_params, args=(x, fx_normalized),
method='Nelder-Mead', bounds=[(0.01, 0.99), (0.1, None), (0.1, None), (0.1, None), (0.1, None)])
# Lấy kết quả tối ưu
p_opt, k1_opt, theta1_opt, k2_opt, theta2_opt = result.x
# In kết quả
print(f"Optimized parameters:")
print(f"p = {p_opt:.4f}")
print(f"k1 = {k1_opt:.4f}")
print(f"theta1 = {theta1_opt:.4f}")
print(f"k2 = {k2_opt:.4f}")
print(f"theta2 = {theta2_opt:.4f}")
# Tính và in log-likelihood tối ưu
optimal_ll = -result.fun
print(f"Optimal log-likelihood: {optimal_ll:.4f}")